Background
- Previous WASM decompilers have poor readability.
- Existing LLM decompilers are not specialized for WASM binaries.
- Stack-based architecture makes the assembly very uncomprehensive.
- Cannot handle fine-grained snippets.
- Cannot handle complicated structures, including nested loops.

Method
1. Dataset construction
- Collected about 52,000 C programs.
- Consists of (WAT, C, Spatial_info, Temporal_info, Offset2String).
- Main idea: String Substitution -> Variable Renaming -> Snippet Slicing
| WAT(Webassembly Text Format) | Snippet of human-readable format of WASM binary |
| C | Snippet of original source code |
| Spatial_info | Function signature (parameters & return values) |
| Temporal_info | Local variables defined before the snippet |
| Offset2String | Mapping from offsets to string constants |
String Substitution
- String substitution enables the model to recover the string value correctly.
- Every string is substituted with an offset from the data segment. (Mapped in ‘Offset2String’)



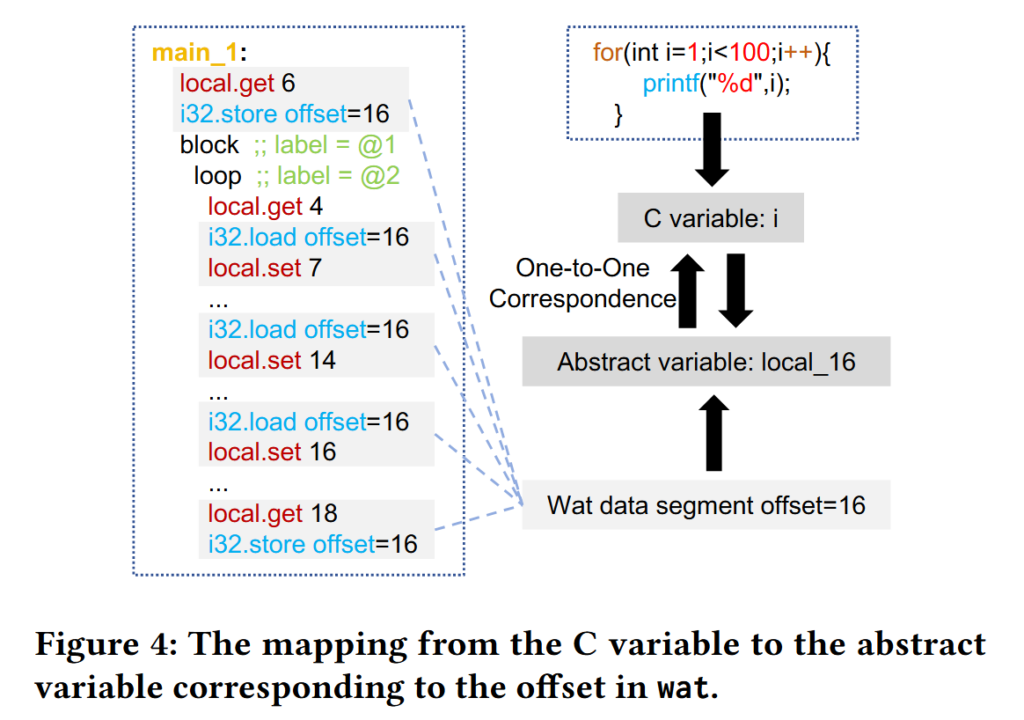
Variable Renaming
- Variable renaming improves the consistency in recovered variable names.
- Renamed the variables of the source code and wat snippets into ‘local_N’
- A variable name is mapped with a specific offset in a function using DWARF information.
Slicing
- Slicing improves nested loop handling capability.
- Codes are sliced to include at most one loop statement.

2. Modeling
- Fine-tuned based on CodeLLaMa-7b-hf.
- Next token prediction (CAUSAL_LM task type)
- Synthesized a prompt (pn) to train the model.
- In the evaluation prompt, cn is excluded.
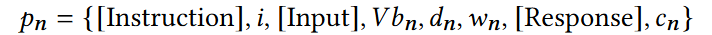
| i | Instruction (i.e. You are a decompiler…) |
| Vbn | Previously defined variables |
| dn | Function signatures |
| wn | WAT code |
| cn | C code |
Evaluation
Similarity
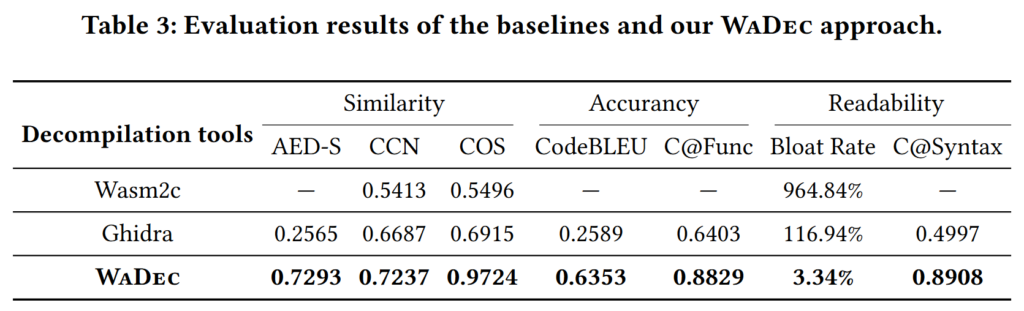
- Evaluated with the test set included in the dataset. About 4,000 C programs were used.
- Overall, the decompiled code shows high similarity to the original source code.
- Metrics
- C@Func = (# functions in decompiled code)/(# total functions)
| AED-S (Normalized AST edit distance) | AST similarity (higher is better) |
| CCN (Cyclomatic complexity) | Program complexity (higher is better) |
| COS (Cosine similarity) | Token similarity (higher is better) |
| CodeBLEU | Structural & dataflow similarity in AST-level (higher is better) |
| C@Func (Function completeness) | Ratio of functions recovered (higher is better) |
| Bloat Rate | Expansion in code lines (lower is better) |
| C@Syntax (Syntax completeness) | Ratio of syntactically flawless statements (higher is better) |
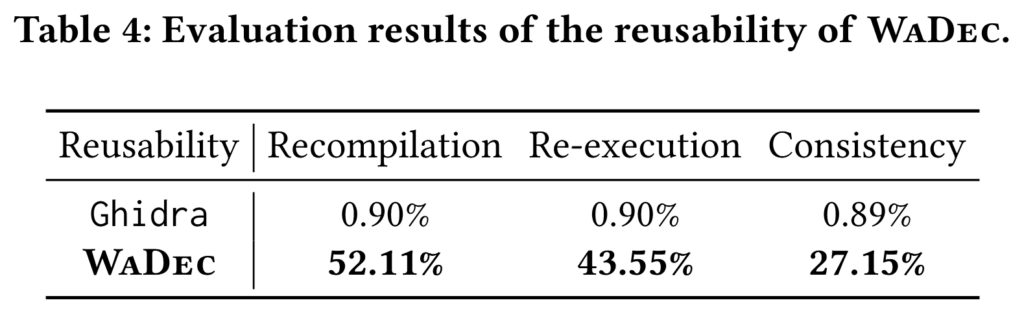
Re-executability
- Acceptable recompilation and re-execution rate
- Low output consistency
Discussion
Variable renaming in the aspect of readability
- Variable renaming might be effective for consistency.
- However, it can cause bad effect to the decompiled code in terms of readability.
- It might be improved by post-processing the variable names using LLM.
CodeBLEU score
- The CodeBLEU score was 0.6353, which is relatively low.
- The authors insist that the CodeBLEU cannot accurately measure the structural similarity.
- This might be due to the rich semantics of C language.
Consistency
- The experiment shows that the outputs of the re-compiled binaries are not consistent.
- It might be challenging to resolve this at this moment, as it is the fundamental issue of the language model.
Evaluated only for non-optimized binaries
- More optimizations may lead the model accuracy to be lowered.
Leave a Reply